第 3 章 内存顺序
来自 《Rust Atomics and Locks》 的翻译文章,英文原文:https://marabos.nl/atomics/memory-ordering.html
在第 2 章中,我们简要介绍了内存顺序的概念。在本章中,我们将深入探讨这个主题,并探索所有可用的内存顺序选项,以及最重要的是,何时使用哪一个。
重新排序和优化
处理器和编译器执行各种技巧,使你的程序尽可能快地运行。例如,处理器可能会确定你的程序中两条特定的连续指令不会相互影响,并不按顺序执行它们,如果这样做更快的话。当一条指令在从主存储器中获取一些数据时被短暂阻断,下面的几条指令可能会被执行,并在第一条指令完成之前完成,只要这不会改变你的程序的行为。同样地,如果编译器有理由相信这可能导致更快的执行,它可能决定重新排序或重写你的程序的一部分。但是,同样地,只有在这不会改变你的程序行为的情况下。
让我们以下面的函数为例:
fn f(a: &mut i32, b: &mut i32) {
*a += 1;
*b += 1;
*a += 1;
}
在这里,编译器肯定会理解这些操作的顺序并不重要,因为在这三个加法操作之间没有发生任何依赖于 *a 或 *b 值的事情。(假设溢出检查被禁用。)正因为如此,它可能会对第二和第三项操作重新排序,然后将前两项合并为一个加法:
fn f(a: &mut i32, b: &mut i32) {
*a += 2;
*b += 1;
}
稍后,在执行这个优化编译程序的功能时,处理器可能由于各种原因,最终在第一个加法之前执行第二个加法,可能是因为 *b 在缓存中可用,而 *a 必须从主存储器中获取。
无论这些优化如何,结果都是一样的: *a被递增 2,*b被递增 1。它们递增的顺序对于程序的其余部分是完全不可见的。
验证一个特定的重新排序或其他优化,不会影响程序行为的逻辑不会考虑其他线程。在我们上面的示例中,这完全没问题,因为唯一的引用 ( &mut i32 ) 保证了没有其他东西可以访问这些值,从而使其他线程无关紧要。唯一会出现问题的情况是,在改变线程之间共享的数据时。或者,换句话说,在使用原子时。这就是为什么我们必须明确地告诉编译器和处理器它们可以用我们的原子操作做什么和不能做什么,因为它们通常的逻辑会忽略线程之间的交互,并且可能允许进行确实会改变程序结果的优化。
有趣的问题是我们如何告诉他们。如果我们想准确地说明什么是可接受的,什么是不可接受的,并发编程可能会变得非常冗长和容易出错,甚至可能是特定于体系结构的:
let x = a.fetch_add(1,
Dear compiler and processor,
Feel free to reorder this with operations on b,
but if there's another thread concurrently executing f,
please don't reorder this with operations on c!
Also, processor, don't forget to flush your store buffer!
If b is zero, though, it doesn't matter.
In that case, feel free to do whatever is fastest.
Thanks~ <3
);
相反,我们只能从一小部分选项中挑选,这些选项由 std::sync::atomic::Ordering 枚举表示,每个原子操作都把它作为一个参数。可用的选项集非常有限,但经过精心挑选,可以很好地适应大多数使用情况。这些排序是非常抽象的,并不直接反映实际的编译器和处理器机制,例如指令重排。这使得你的并发代码有可能是独立于架构的,并且是面向未来的。它允许在不知道每个当前和未来的处理器和编译器版本的细节的情况下进行验证。
Rust 中可用的顺序是:
宽松顺序: Ordering::Relaxed
释放和获取顺序: Ordering::{Release, Acquire, AcqRel}
顺序一致(Sequentially consistent ordering): Ordering::SeqCst
在 C++ 中,还有一种叫做 消费顺序(consume ordering) 的东西,它在 Rust 中被故意省略了,但讨论起来也很有趣。
内存模型
不同的内存顺序选项有一个严格的正式定义,以确保我们确切地知道我们被允许假设什么,并让编译器编写者确切地知道他们需要向我们提供什么保证。为了与具体的处理器架构的细节脱钩,内存顺序是以抽象的内存模型来定义的。
Rust的内存模型主要是从C++中复制过来的,它不匹配任何现有的处理器架构,而是一个抽象的模型,有一套严格的规则,试图代表所有当前和未来架构的最大共同点,同时也给编译器足够的自由,在分析和优化程序时做出有用的假设。
我们已经在第 1 章的“借用和数据竞争”中看到了内存模型的一部分,我们在其中讨论了数据竞争如何导致未定义的行为。 Rust 的内存模型允许并发原子存储,但将对同一变量的并发非原子存储视为数据竞争,从而导致未定义的行为。
然而,在大多数处理器架构上,原子存储和常规非原子存储之间实际上没有区别,正如我们将在第 7 章中看到的那样。有人可能会争辩说内存模型比必要的限制更多,但是这些严格的规则使编译器和程序员更容易推理程序,并为未来的发展留出空间。
先行发生关系(Happens-Before Relationship)
内存模型根据 先行发生关系(happens-before relationships) 定义操作发生的顺序。这意味着作为一个抽象模型,它不讨论机器指令、缓存、缓冲区、时序、指令重新排序、编译器优化等,而是只定义保证一件事先于另一件事发生的情况,并且留下所有其他未定义的顺序。
基本的先行发生规则是同一线程内发生的所有事情都按顺序发生。如果一个线程正在执行 f(); g(); ,那么 f() 发生在 g()之前 。
然而,在线程之间,先行发生关系只发生在少数特殊情况下,例如当产生(spawning)和加入(joining)一个线程,解锁和锁定一个互斥体,以及通过使用非宽松(non-relaxed)内存顺序的原子操作。 Relaxed 内存顺序是最基本(也是最高效)的内存顺序,它本身永远不会导致任何跨线程先行发生关系。
为了探究这意味着什么,让我们看一下下面的示例,其中我们假设 a 和 b 由不同的线程同时执行:
static X: AtomicI32 = AtomicI32::new(0);
static Y: AtomicI32 = AtomicI32::new(0);
fn a() {
X.store(10, Relaxed); // 1
Y.store(20, Relaxed); // 2
}
fn b() {
let y = Y.load(Relaxed); // 3
let x = X.load(Relaxed); // 4
println!("{x} {y}");
}
如上所述,基本的先行发生规则是同一线程内发生的所有事情都按顺序发生。在这种情况下:(1)发生在(2)之前,(3)发生在(4)之前,如图3-1所示。由于我们使用宽松的内存顺序(relaxed memory orderings),因此在我们的示例中没有其他先行发生关系。
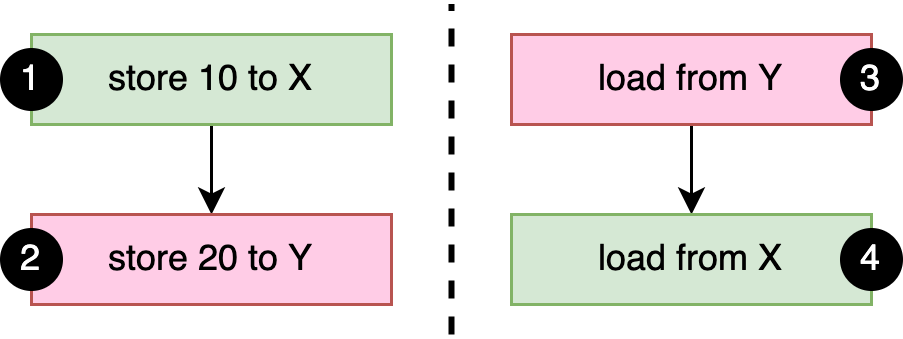
如果 a 或 b 中的任何一个在另一个开始之前完成,输出将是 0 0 或 10 20。如果 a 和 b 同时运行,很容易看出输出结果是 10 0。发生这种情况的一种方式是,如果操作以这种顺序运行: 3 1 2 4。
更有趣的是,输出也可以是 0 20 ,尽管这四项操作不可能有全局一致的顺序,从而导致这种结果。当 (3) 执行时,与 (2) 没有先行发生关系,也就是说它可以加载 0 或 20。当 (4) 执行时,与 (1) 没有先行发生关系,这意味着它可以加载 0 或 10 。鉴于此,输出 0 20 是一个有效的结果。
需要理解的重要且违反直觉的事情是,操作 (3) 加载值 20 不会导致与 (2) 发生先行关系,即使该值是由 (2) 存储的。我们对“之前(before)”概念的直观理解当事情不一定以全局一致的顺序发生时,例如当涉及指令重新排序时,它就会崩溃。
一种更实用、更直观但不那么正式的理解是,从执行 b 的线程的角度来看,操作 (1) 和 (2) 的发生顺序可能相反。
产生和加入(Spawning and Joining)
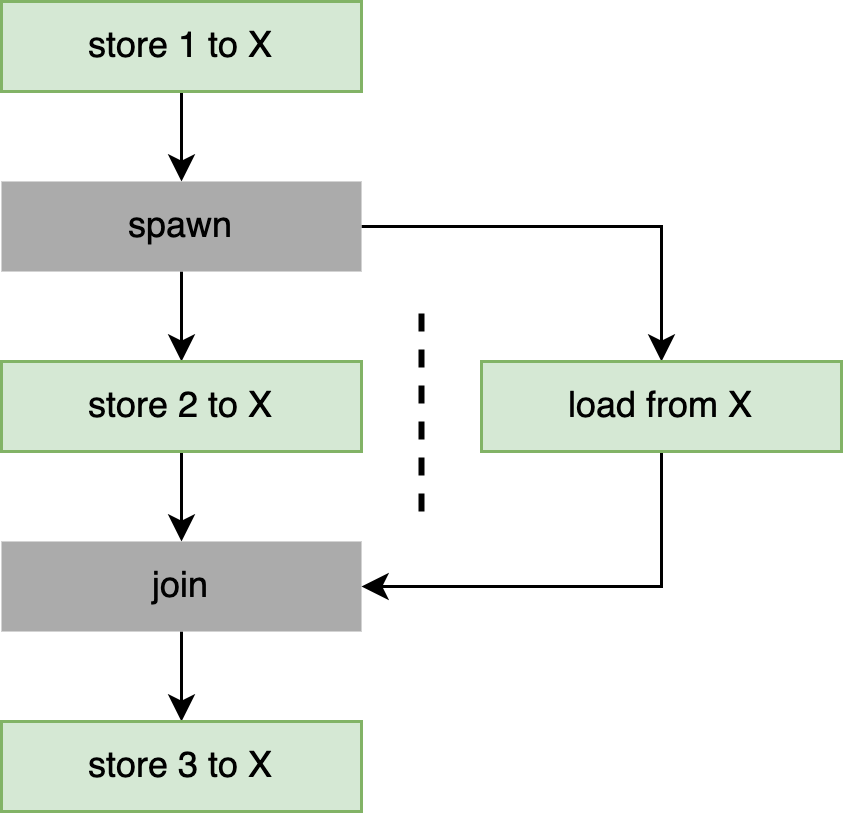
产生线程会在 spawn() 调用之前发生的事情与新线程之间创建先行关系。类似地,加入(join)线程会在加入的线程与 join() 调用之后发生的事情之间创建先行关系。
为了演示,以下示例中的断言不能失败:
static X: AtomicI32 = AtomicI32::new(0);
fn main() {
X.store(1, Relaxed);
let t = thread::spawn(f);
X.store(2, Relaxed);
t.join().unwrap();
X.store(3, Relaxed);
}
fn f() {
let x = X.load(Relaxed);
assert!(x == 1 || x == 2);
}
由于 join 和 spawn 操作形成的先行发生关系,我们可以肯定地知道来自 X 的加载发生在第一个存储之后,但在最后一个存储之前,如图 3-2 所示。但是,它观察的是第二次存储之前还是之后的值是不可预测的。换句话说,它可以加载 1 或 2,但不能加载 0 或 3。
宽松顺序(Relaxed Ordering)
虽然使用宽松内存顺序的原子操作不提供任何先行发生关系,但它们确实保证了每个单独原子变量的总修改顺序(total modification order)。这意味着从每个线程的角度来看,同一个原子变量的所有修改都以相同的顺序发生。
为了演示这意味着什么,请考虑以下示例,其中我们假设 a 和 b 由不同线程同时执行:
static X: AtomicI32 = AtomicI32::new(0);
fn a() {
X.fetch_add(5, Relaxed);
X.fetch_add(10, Relaxed);
}
fn b() {
let a = X.load(Relaxed);
let b = X.load(Relaxed);
let c = X.load(Relaxed);
let d = X.load(Relaxed);
println!("{a} {b} {c} {d}");
}
本例中只有一个线程修改了 X ,由此可见 X 的修改顺序只有一种可能:0→5→15。它从0开始,然后变成5,最后变成15。线程无法观察到来自 X 的任何与此总修改顺序不一致的值。这意味着 "0 0 0 0" 、 "0 0 5 15" 和 "0 15 15 15" 是其他线程中打印语句的一些可能结果,而 "0 5 0 15" 或 "0 0 10 15" 的输出是不可能的。
即使原子变量有多个可能的修改顺序,所有线程也会就一个顺序达成一致。
让我们用两个单独的函数替换 a , a1 和 a2 ,我们假设它们分别由一个单独的线程执行:
fn a1() {
X.fetch_add(5, Relaxed);
}
fn a2() {
X.fetch_add(10, Relaxed);
}
假设这些是唯一修改 X 的线程,现在有两种可能的修改顺序:0→5→15 或 0→10→15,具体取决于哪个 fetch_add 操作先执行。无论发生哪种情况,所有线程都遵循相同的顺序。 因此,即使我们有数百个额外线程都在运行我们的 b() 函数,我们也知道如果其中一个线程打印 10 ,则顺序必须是 0→10→15,它们都不可能打印出 5。
在第 2 章中,我们看到了几个用例示例,其中对单个变量的总修改顺序保证就足够了,从而使宽松的内存顺序足够了。然而,如果我们尝试比这些例子更高级的东西,我们很快就会发现我们需要比宽松的内存顺序更强大的东西。
凭空值(Out-of-Thin-Air Values)
当操作以循环方式相互依赖时,缺乏围绕宽松内存顺序序的排序保证可能会导致一些理论上的复杂化。
为了演示,这是一个人为的示例,其中两个线程从一个原子加载一个值并将其存储在另一个中:
static X: AtomicI32 = AtomicI32::new(0);
static Y: AtomicI32 = AtomicI32::new(0);
fn main() {
let a = thread::spawn(|| {
let x = X.load(Relaxed);
Y.store(x, Relaxed);
});
let b = thread::spawn(|| {
let y = Y.load(Relaxed);
X.store(y, Relaxed);
});
a.join().unwrap();
b.join().unwrap();
assert_eq!(X.load(Relaxed), 0); // Might fail?
assert_eq!(Y.load(Relaxed), 0); // Might fail?
}
似乎很容易得出结论, X 和 Y 的值永远不会是0以外的任何值,因为存储操作只存储从这些相同的原子加载的值,这些值永远只为0。
然而,如果我们严格遵循理论内存模型,我们就不得不接受我们的循环推理,并得出我们可能错了的可怕结论。事实上,内存模型在技术上允许 X 和 Y 最后都为 37 或任何其他值的结果,从而使断言失败。
由于缺乏顺序保证,这两个线程的加载操作可能都看到另一个线程的存储操作的结果,允许操作顺序循环: 我们将 37 存储在 Y 中,因为我们从 X 加载了 37,而将 37 存储到 X 是因为我们从 Y 加载了 37,这是我们存储在 Y 中的值。
幸运的是,这种凭空出现的值的可能性被普遍认为是理论模型中的错误,而不是您在实践中需要考虑的问题。如何在模型允许此类异常的情况下,形式化宽松内存顺序的理论问题尚未解决。虽然这是形式验证的一个障碍,让许多理论家彻夜难眠,但我们其他人可以在幸福的无知中放松,因为他们知道这在实践中不会发生。
释放和获取顺序(Release and Acquire Ordering)
释放(Release) 和 获取(Acquire) 内存顺序成对使用,以形成线程之间的先行发生关系。 Release 内存顺序适用于存储操作,而 Acquire 内存顺序适用于加载操作。
当获取加载操作观察到释放存储操作的结果时,就会形成先行发生关系。在这种情况下,存储和它之前的一切,都发生在加载和它之后的一切之前。
当使用 Acquire 进行获取和修改(fetch-and-modify)或比较和交换(compare-and-exchange)操作时,它仅适用于加载值的操作部分。同样, Release 仅适用于操作的存储部分。 AcqRel 用来表示 Acquire 和 Release 的组合,使得load 都使用获取顺序(acquire ordering),store 都使用释放顺序(release ordering)。
让我们看一个例子,看看它在实践中是如何使用的。在下面的示例中,我们将一个 64 位整数从派生线程发送到主线程。 我们使用一个额外的原子布尔值来向主线程指示整数已存储并准备好读取。
use std::sync::atomic::Ordering::{Acquire, Release};
static DATA: AtomicU64 = AtomicU64::new(0);
static READY: AtomicBool = AtomicBool::new(false);
fn main() {
thread::spawn(|| {
DATA.store(123, Relaxed);
READY.store(true, Release); // Everything from before this store ..
});
while !READY.load(Acquire) { // .. is visible after this loads `true`.
thread::sleep(Duration::from_millis(100));
println!("waiting...");
}
println!("{}", DATA.load(Relaxed));
}
当生成的线程完成数据存储时,它使用释放存储将 READY 标志设置为 true 。当主线程通过其 acquire-load 操作观察到这一点时,就会在这两个操作之间建立 先行发生关系,如图 3-3 所示。 在这一点上,我们肯定知道在释放存储到 READY 之前发生的一切对于获取加载之后发生的一切都是可见的。具体来说,当主线程从 DATA 加载时,我们肯定知道它会加载后台线程存储的值。这个程序只能在最后一行打印一个可能的结果: 123 。
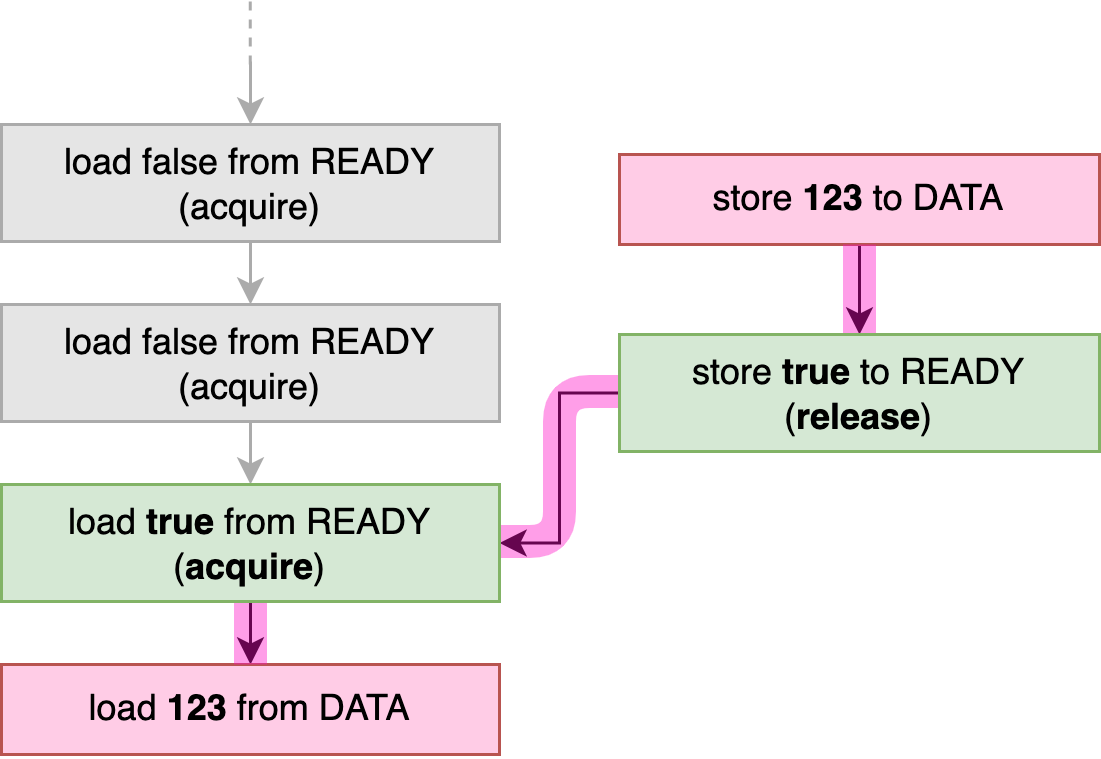
如果我们在这个例子中对所有操作使用宽松的内存顺序,主线程可能会看到 READY 翻转到 true ,同时仍然从 DATA 加载 0。
提示
“release”和“acquire”这两个名称是基于它们最基本的用例:一个线程通过原子方式将一些值存储到原子变量来释放数据,另一个线程通过原子方式加载该值来获取它。这正是我们解锁(释放)互斥锁并随后在另一个线程上锁定(获取)它时发生的情况。
在我们的示例中,来自 READY 标志的 先行发生关系保证了 DATA 的存储和加载操作不会同时发生。这意味着我们实际上不需要这些操作是原子的。
然而,如果我们简单地尝试为我们的数据变量使用常规的非原子类型,编译器将拒绝我们的程序,因为 Rust 的类型系统不允许我们在另一个线程也借用它们时从一个线程改变它们。类型系统不会神奇地理解我们在这里创建的先行发生关系。一些 unsafe 代码是必要的,以向编译器保证我们已经仔细考虑了这一点,并且我们确信我们没有违反任何规则,如下所示:
static mut DATA: u64 = 0;
static READY: AtomicBool = AtomicBool::new(false);
fn main() {
thread::spawn(|| {
// Safety: Nothing else is accessing DATA,
// because we haven't set the READY flag yet.
unsafe { DATA = 123 };
READY.store(true, Release); // Everything from before this store ..
});
while !READY.load(Acquire) { // .. is visible after this loads `true`.
thread::sleep(Duration::from_millis(100));
println!("waiting...");
}
// Safety: Nothing is mutating DATA, because READY is set.
println!("{}", unsafe { DATA });
}
More Formally
当获取加载操作观察到释放存储操作的结果时,就会形成先发生关系。但是,这是什么意思?
想象一下,两个线程都将一个 7 释放到同一个原子变量中,而第三个线程从该变量中加载一个 7。第三个线程现在与第一个线程或第二个线程有一个先行发生关系吗?这取决于它加载的是 "哪一个 7":是来自线程一的还是来自线程二的。(也可能是一个不相关的 7。)这使我们得出这样的结论:尽管 7 等于 7,但两个线程的两个 7 有一些不同。
思考这个问题的方法是我们在 "宽松顺序 "中谈到的总修改顺序:发生在一个原子变量上的所有修改的有序列表。即使同一个值被多次写入同一个变量,这些操作中的每一个都代表了该变量的总修改顺序中的一个独立事件。当我们加载一个值时,所加载的值与这个每个变量 "时间轴 "上的一个特定点相匹配,这告诉我们可能要与哪个操作同步。
例如,如果原子的总修改顺序是
初始化为0
释放-存储(Release-store) 7 (来自线程2)
宽松存储(Relaxed-store)6
释放存储(Release-store)7(来自线程1)。
那么获取-加载 7 将与第二个事件的释放-存储或最后一个事件的释放-存储同步。然而,如果我们之前(就先行发生关系而言)看到了 6,我们就知道我们看到的是最后一个 7,而不是第一个,这意味着我们现在与线程1有先行发生的关系,而不是与线程2。
有一个额外的细节,那就是一个释放存储的值可以被任何数量的获取-修改和比较-交换操作所修改,同时仍然导致与读取最终结果的获取-加载之间的先行发生关系。
例如,想象一个具有以下总修改顺序的原子变量:
Initialized at 0
Release-store 7
Relaxed-fetch-and-add 1, changing 7 to 8
Release-fetch-and-add 1, changing 8 to 9
Release-store 7
Relaxed-swap 10, changing 7 to 10
现在,如果我们从这个变量中获取-加载一个 9,我们不仅与第四个操作(存储该值)建立了先行发生关系,而且与第二个操作(存储了一个 7)建立了先行发生关系,即使第三个操作操作使用宽松的内存顺序。
类似地,如果我们从这个变量中获取加载一个 10,它是由一个宽松的操作写入的,我们仍然会与第五个操作(存储一个 7)建立一个先行发生关系。因为这只是一个常规的存储操作(不是获取和修改或比较和交换操作),它打破了链条:我们没有与任何其他操作建立先行发生关系。
示例:锁
互斥锁是释放和获取顺序的最常见用例(请参阅第 1 章中的“锁定:互斥锁和读写锁”)。锁定时,他们使用原子操作来检查它是否已解锁,使用获取顺序,同时还(原子地)将状态更改为“已锁定”。解锁时,他们使用释放顺序将状态设置回“解锁”。这意味着在解锁互斥量和随后锁定它之间将存在先行发生关系。
下面是这种模式的演示:
static mut DATA: String = String::new();
static LOCKED: AtomicBool = AtomicBool::new(false);
fn f() {
if LOCKED.compare_exchange(false, true, Acquire, Relaxed).is_ok() {
// Safety: We hold the exclusive lock, so nothing else is accessing DATA.
unsafe { DATA.push('!') };
LOCKED.store(false, Release);
}
}
fn main() {
thread::scope(|s| {
for _ in 0..100 {
s.spawn(f);
}
});
}
正如我们在第 2 章的“比较和交换操作”中简要介绍的,比较和交换操作需要两个内存顺序参数:一个是比较成功和存储发生的情况,另一个是比较失败和存储没有发生的情况。在 f 中,我们尝试将 LOCKED 从 false 更改为 true ,只有在成功的情况下才访问 DATA 。所以,我们只关心成功的内存顺序。如果 compare_exchange 操作失败,那一定是因为 LOCKED 已经设置为 true ,在这种情况下, f 不会做任何事情。这与常规互斥锁上的 try_lock 操作相匹配。
提示
细心的读者可能已经注意到,比较和交换操作也可能是交换操作,因为在已锁定时将 true 交换为 true 不会改变代码的正确性:
// 这也有效。
if LOCKED.swap(true, Acquire) == false {
…
}
由于获取和释放内存顺序,我们可以确定没有两个线程可以同时访问 DATA 。如图 3-4 所示,之前对 DATA 的任何访问都发生在随后的释放-存储 false 到 LOCKED 之前,而这又发生在下一个获取-比较-交换(或获取-交换)操作之前,该操作将 false 变为 true,而这又发生在对 DATA 的下一次访问。
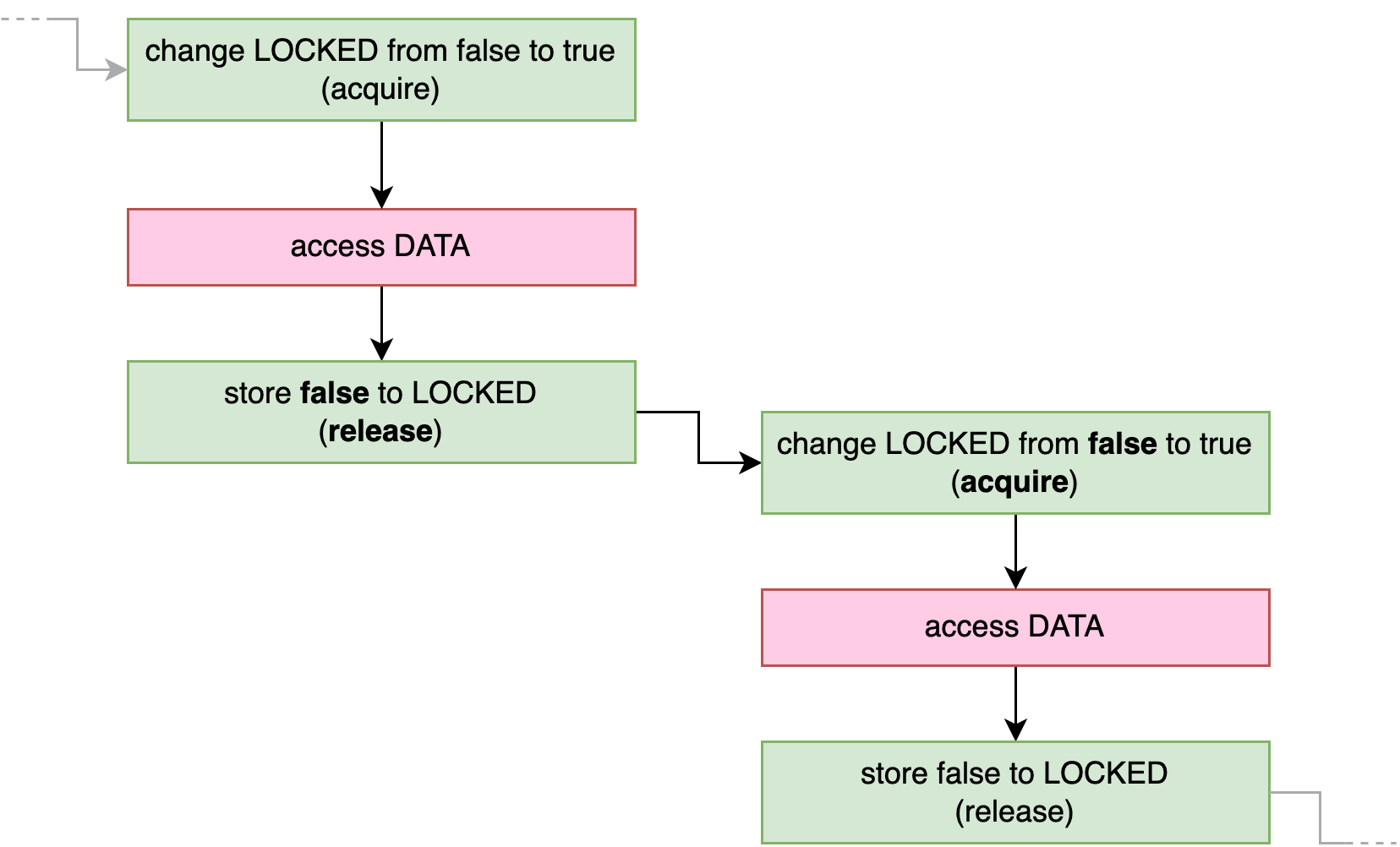
在第 4 章中,我们会将这个概念转化为可重用的类型:自旋锁(spin lock)。
示例:间接延迟初始化
在第 2 章的“示例:惰性一次性初始化”中,我们实现了全局变量的惰性初始化,使用比较和交换操作来处理多个线程竞相同时初始化值的情况。因为该值是一个非零的 64 位整数,所以我们能够使用 AtomicU64 来存储它,在初始化它之前使用零作为占位符。
为了对一个更大的数据类型做同样的处理,而这个数据类型又不适合在一个单一的原子变量中使用,我们需要寻找一种替代方法。
在这个例子中,假设我们想保持非阻塞行为,所以线程永远不会等待另一个线程,而是争先恐后地从第一个线程中获取值来完成初始化。这意味着我们仍然需要能够在一次原子操作中从 "未初始化 "到 "完全初始化"。
正如软件工程的基本定理告诉我们的那样,计算机科学中的每一个问题都可以通过增加一个间接层来解决,这个问题也不例外。由于我们无法将数据放入单个原子变量中,因此我们可以使用原子变量来存储指向数据的指针。
AtomicPtr<T> 是 *mut T 的原子版本:指向 T 的指针。我们可以使用空指针作为初始状态的占位符,并使用比较和交换操作以原子方式将其替换为指向新分配的、完全初始化的 T 的指针,然后其他线程可以读取它。
由于我们不仅共享包含指针的原子变量,而且共享它指向的数据,我们不能再像第 2 章那样使用宽松的内存顺序。我们需要确保分配和初始化数据不会与读取数据发生冲突。换句话说,我们需要对存储和加载操作使用释放和获取顺序,以确保编译器和处理器不会破坏我们的代码——例如——重新排序指针的存储和初始化数据本身。
这导致我们对一些称为 Data 的任意数据类型进行以下实现:
use std::sync::atomic::AtomicPtr;
fn get_data() -> &'static Data {
static PTR: AtomicPtr<Data> = AtomicPtr::new(std::ptr::null_mut());
let mut p = PTR.load(Acquire);
if p.is_null() {
p = Box::into_raw(Box::new(generate_data()));
if let Err(e) = PTR.compare_exchange(
std::ptr::null_mut(), p, Release, Acquire
) {
// Safety: p comes from Box::into_raw right above,
// and wasn't shared with any other thread.
drop(unsafe { Box::from_raw(p) });
p = e;
}
}
// Safety: p is not null and points to a properly initialized value.
unsafe { &*p }
}
如果我们从 PTR 获取加载的指针是非空的,我们假设它指向已经初始化的数据,并构造对该数据的引用。
但是,如果它仍然为 null,我们将生成新数据并将其存储在使用 Box::new 的新分配中。然后,我们使用 Box::into_raw 将此 Box 转换为原始指针,因此我们可以尝试使用比较和交换操作将其存储到 PTR 中。如果另一个线程赢得初始化竞争,则 compare_exchange 失败,因为 PTR 不再为空。如果发生这种情况,我们将原始指针变回 Box 以使用 drop 释放它,避免内存泄漏,并继续使用另一个线程存储在 PTR 中的指针。
最后一个 unsafe 块的安全注释陈述了我们的假设,即它指向的数据已经被初始化。请注意这如何包括对事情发生顺序的假设。为了确保我们的假设成立,我们使用释放和获取内存顺序来确保初始化数据确实发生了————在创建对它的引用之前。
我们在两个地方加载一个潜在的非空(即已初始化)指针:通过 load 操作和失败时通过 compare_exchange 操作。因此,如上所述,我们需要对 load 内存顺序和 compare_exchange 失败内存顺序都使用 Acquire ,以便能够与存储指针的操作同步。此存储在 compare_exchange 操作成功时发生,因此我们必须使用 Release 作为其成功顺序。
图 3-5 显示了三个线程调用 get_data() 的情况下的操作和先行发生关系的可视化。在这种情况下,线程 A 和 B 都观察到一个空指针,并且都尝试初始化原子指针。线程 A 赢得了竞争,导致线程 B 的 compare_exchange 操作失败。线程 C 只有在线程 A 初始化后才观察原子指针。最终结果是所有三个线程最终都使用线程 A 分配的box。
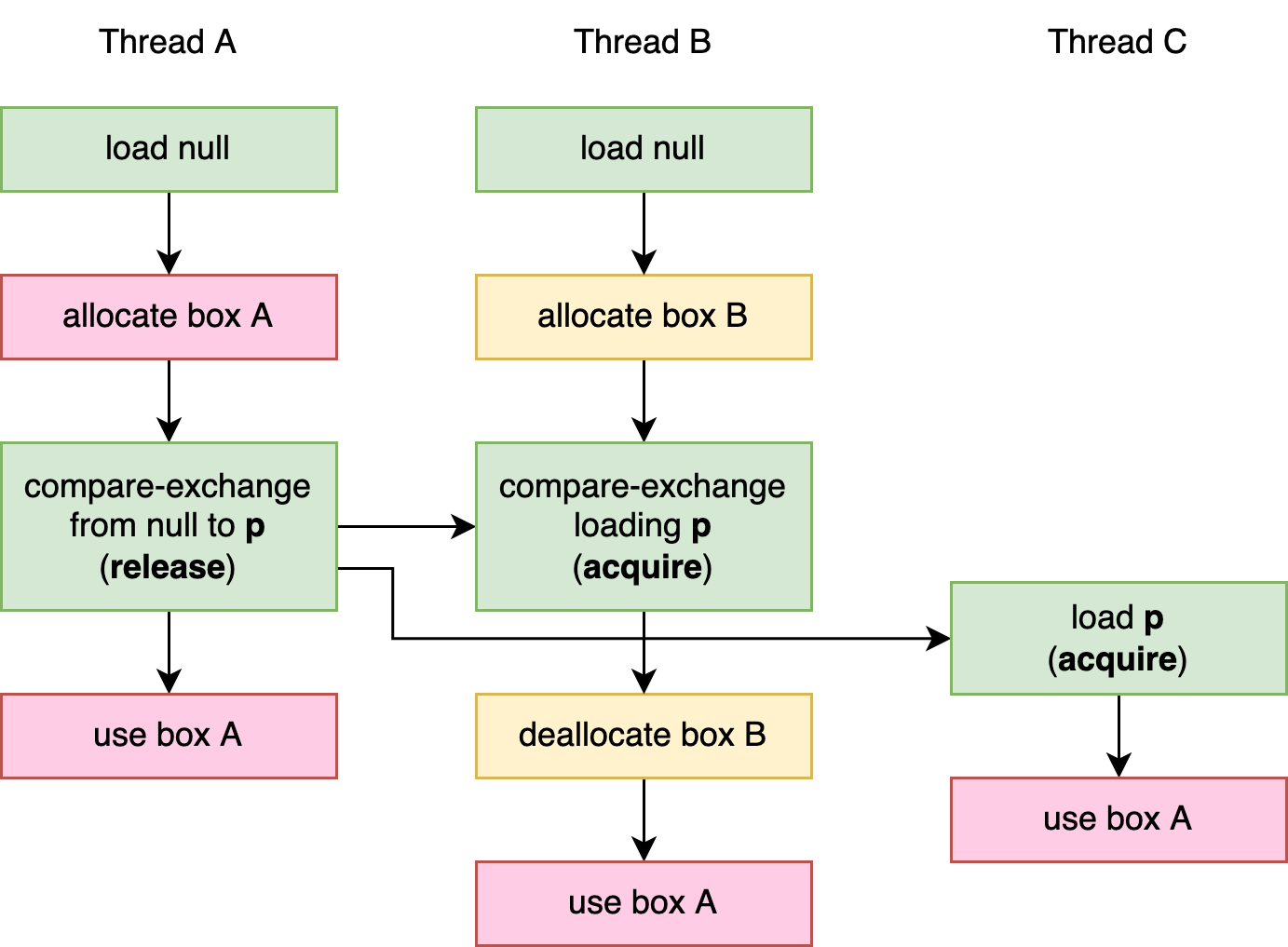
消费顺序(Consume Ordering)
让我们仔细看一下,上一个例子中的内存顺序。如果我们抛开严格的内存模型,从更实际的角度来考虑,我们可以说释放顺序可以防止数据的初始化通过与其他线程共享指针的存储操作进行重新排序。这很重要,否则其他线程可能会在数据完全初始化之前看到它。
类似地,我们可以将获取顺序解释为防止重新排序,从而导致在加载指针之前访问数据。然而,人们可能有理由怀疑这在实践中是否有意义。在知道数据地址之前如何访问数据?我们可能会得出结论,比获取顺序更弱的东西可能就足够了。我们是对的:这种较弱的顺序称为 消费顺序。
消费顺序基本上是获取顺序的轻量级(更高效)变体,其同步效果仅限于依赖于加载值的东西。
这意味着,如果你从一个原子变量消费加载(consume-load)一个释放存储(release-stored)值 x ,那么,基本上,该存储发生在依赖表达式如 *x 、 array[x] 或 table.lookup(x + 1) 的评估之前,但是不一定在独立操作之前,比如读取另一个我们不需要 x 值的变量。
现在有好消息和坏消息。
好消息是——在所有现代处理器架构上——消费顺序是通过与宽松顺序完全相同的指令实现的。换句话说,消费顺序可以是“免费的”,但至少在某些平台上,获取顺序并非如此。
坏消息是没有编译器真正实现消费顺序。
事实证明,不仅很难定义“依赖”评估的概念,而且在转换和优化程序时更难保持这种依赖性完整无缺。例如,编译器可能能够将 x + 2 - x 优化为仅 2 ,从而有效地降低对 x 的依赖性。如果编译器能够对 x 或数组元素的可能值进行任何逻辑推论,则此问题的更细微变化可能会发生在更现实的表达式(如 array[x] )中。当考虑到控制流时,问题变得更加复杂,例如 if 语句或函数调用。
因此,为了安全起见,编译器将 消费顺序(consume ordering) 升级为 获取顺序(acquire ordering)。 C++20 标准甚至明确不鼓励使用消费顺序,指出除了获取顺序之外的实现被证明是不可行的。
将来可能会找到消费顺序的可行定义和实现。然而,在那个时间到来之前,Rust 不会暴露 Ordering::Consume 。
顺序一致的顺序(Sequentially Consistent Ordering)
最强的内存顺序是顺序一致的顺序: Ordering::SeqCst 。它包括获取顺序(对于加载)和释放顺序(对于存储)的所有保证,并且还保证全局一致的操作顺序。
这意味着在程序中使用 SeqCst 顺序的每个操作都是所有线程都同意的单个总顺序的一部分。此总顺序与每个单独变量的总修改顺序一致。
由于它严格地强于获取和释放的内存顺序,因此在释放-获取对中,顺序一致的加载或存储可以取代获取-加载或释放-存储,形成先行发生关系。换句话说,一个获取-加载不仅可以与释放-存储形成先行发生关系,还可以与顺序一致的存储形成先行发生关系,反之亦然。
提示
只有当先行发生关系的双方都使用 SeqCst 顺序时,才能保证与 SeqCst 操作的单次总顺序一致。
虽然这看起来是最容易推理的内存顺序,但实际上 SeqCst 顺序几乎从来都不是必需的。在几乎所有情况下,定期获取和释放顺序就足够了。
这是一个依赖于顺序一致的有序操作的示例:
use std::sync::atomic::Ordering::SeqCst;
static A: AtomicBool = AtomicBool::new(false);
static B: AtomicBool = AtomicBool::new(false);
static mut S: String = String::new();
fn main() {
let a = thread::spawn(|| {
A.store(true, SeqCst);
if !B.load(SeqCst) {
unsafe { S.push('!') };
}
});
let b = thread::spawn(|| {
B.store(true, SeqCst);
if !A.load(SeqCst) {
unsafe { S.push('!') };
}
});
a.join().unwrap();
b.join().unwrap();
}
两个线程首先将自己的原子布尔值设置为 true ,以警告其他线程它们即将访问 S ,然后检查对方的原子布尔值,看看它们是否可以安全地访问 S ,而不会导致数据竞争。
如果两个存储操作都发生在任一加载操作之前,则可能两个线程都不会访问 S 。但是,不可能两个线程都访问 S 并导致未定义的行为,因为顺序一致的顺序保证只有其中一个可以赢得竞争。在每一个可能的单一全序中,第一个操作将是存储操作,这会阻止其他线程访问 S 。
实际上, SeqCst 的所有实际使用都涉及类似的存储模式,该模式必须在同一线程上的后续加载之前全局可见。对于这些情况,一种可能更有效的替代方法是结合 SeqCst 栅栏(fence)使用宽松操作,我们将在接下来探讨。
栅栏(Fences)
除了对原子变量的操作之外,还有一件事我们可以应用内存顺序:原子栅栏(atomic fences)。
std::sync::atomic::fence 函数表示一个原子栅栏,可以是释放栅栏 ( Release )、获取栅栏 ( Acquire ),或两者兼而有之( AcqRel 或 SeqCst )。 SeqCst 栅栏还参与顺序一致的总顺序。
原子栅栏允许您将内存顺序与原子操作分开。如果您想将内存顺序应用于多个操作,或者您只想有条件地应用它,这将很有用。
从本质上讲,释放存储可以拆分为释放栅栏,然后是(宽松的)存储,获取-加载可以拆分为(宽松的)加载,然后是获取栅栏:

但是,使用单独的栅栏可能会导致额外的处理器指令,这可能会稍微降低效率。
更重要的是,与释放存储或获取加载不同,栅栏不绑定到任何单个原子变量。这意味着单个栅栏可以同时用于多个变量。
形式上,如果释放栅栏后面(在同一线程上)有任何原子操作(存储我们正在同步的获取操作观察到的值),则释放栅栏可以取代先行发生关系中的释放操作。类似地,如果获取栅栏之前(在同一线程上)有任何加载由释放操作存储的值的原子操作,则获取栅栏可以代替任何获取操作。
综上所述,这意味着如果释放栅栏之后的任何存储被获取栅栏之前的任何加载观察到,则在释放栅栏和获取栅栏之间创建了先行发生关系。
例如,假设我们有一个线程执行一个释放栅栏,然后是对不同变量的三个原子存储操作,另一个线程从这些相同的变量执行三个加载操作,然后是一个获取栅栏,如下所示:

在这种情况下,如果线程 2 上的任何加载操作从线程 1 的相应存储操作加载值,则线程 1 上的释放栅栏发生在线程 2 上的获取栅栏之前。
栅栏不必直接在原子操作之前或之后。任何其他事情都可能发生在两者之间,包括控制流。这可用于使栅栏有条件,类似于比较和交换操作如何同时具有成功和失败顺序。
例如,如果我们使用获取内存顺序从原子变量加载指针,我们可以使用栅栏仅在指针不为空时应用获取顺序:

如果通常期望指针为空,这可能是有益的,以避免在不必要时获取内存顺序。
让我们看一个更复杂的释放和获取栅栏的用例:
use std::sync::atomic::fence;
static mut DATA: [u64; 10] = [0; 10];
const ATOMIC_FALSE: AtomicBool = AtomicBool::new(false);
static READY: [AtomicBool; 10] = [ATOMIC_FALSE; 10];
fn main() {
for i in 0..10 {
thread::spawn(move || {
let data = some_calculation(i);
unsafe { DATA[i] = data };
READY[i].store(true, Release);
});
}
thread::sleep(Duration::from_millis(500));
let ready: [bool; 10] = std::array::from_fn(|i| READY[i].load(Relaxed));
if ready.contains(&true) {
fence(Acquire);
for i in 0..10 {
if ready[i] {
println!("data{i} = {}", unsafe { DATA[i] });
}
}
}
}
提示
std::array::from_fn 是一种将某项执行一定次数并将结果收集到数组中的简单方法。
在此示例中,10 个线程执行一些计算并将其结果存储在一个(非原子)共享变量中。每个线程都设置一个原子布尔值,以指示数据已准备好由主线程使用正常的释放存储读取。主线程等待半秒,检查所有 10 个布尔值以查看哪些线程已完成,并打印准备就绪的结果。
主线程没有使用 10 个获取加载操作来读取布尔值,而是使用了宽松的操作和一个获取栅栏。它在读取数据之前执行栅栏,但前提是有数据要读取。
虽然在这个特定示例中,可能完全没有必要为这种优化付出任何努力,但在构建高效并发数据结构时,这种用于节省额外获取操作开销的模式可能很重要。
SeqCst 栅栏既是释放栅栏又是获取栅栏(就像 AcqRel ),也是顺序一致操作的单个总顺序的一部分。但是,只有栅栏是总顺序的一部分,而它之前或之后的原子操作不一定。这意味着与释放或获取操作不同,顺序一致的操作不能拆分为宽松操作和内存栅栏。
编译器栅栏(Compiler Fences)
除了常规的原子栅栏外,Rust 标准库还提供了一个编译器栅栏: std::sync::atomic::compiler_fence 。它的签名与我们上面讨论的常规 fence() 的签名相同,但其效果仅限于编译器。与常规原子栅栏不同,它不会阻止处理器,例如,重新排序指令。在栅栏的绝大多数用例中,编译器栅栏是不够的。
当实现 Unix 信号处理程序或嵌入式系统上的中断时,可能会出现一个潜在的用例。这些是可以突然中断线程以在同一处理器内核上临时执行不相关功能的机制。因为它发生在同一个处理器内核上,所以处理器可能影响内存顺序的通常方式不适用。 (第 7 章对此有更多介绍。)在这种情况下,编译器栅栏可能就足够了,可能会节省一条指令并有望提高性能。
另一个用例涉及进程范围的内存屏障。这种技术不属于 Rust 内存模型的范围,并且仅在某些操作系统上受支持:在 Linux 上通过 membarrier 系统调用,在 Windows 上使用 FlushProcessWriteBuffers 函数。它有效地允许线程将(顺序一致的)原子栅栏强制注入所有并发运行的线程。这使我们能够用一侧的轻量级编译器栅栏和另一侧的重量级进程范围屏障替换两个匹配的栅栏。如果轻量级栅栏一侧的代码执行得更频繁,则可以提高整体性能。 (有关更多详细信息以及在 Rust 中使用此类屏障的跨平台方式,请参阅 crates.io 上 membarrier crate 的文档。)
编译器栅栏也可以是一个有趣的工具,用于探索处理器对内存顺序的影响。在第 7 章的“实验”中,我们将通过用编译器栅栏替换常规栅栏来故意破坏我们的代码。这将使我们在使用错误的内存顺序时,体验处理器微妙但潜在的灾难性影响。
常见的误解
关于内存顺序存在很多误解。在我们结束本章之前,让我们回顾一下最常见的。
误解:我需要强大的内存顺序来确保更改“立即”可见。
一个常见的误解是,使用像 Relaxed 这样的弱内存顺序意味着对原子变量的更改可能永远不会到达另一个线程,或者只有在显着延迟之后才会到达。 “relaxed”这个名字听起来好像什么都没有发生,直到某些东西迫使硬件的某些部分唤醒,并做它应该做的事情而不是放松。
事实上,内存模型根本没有说明任何时序。它只定义某些事情发生的顺序;而不是您可能需要等待多长时间。一台假想的计算机,其中需要数年时间才能将数据从一个线程获取到另一个线程,这是非常不可用的,但可以完美地满足内存模型。
在现实生活中,内存顺序是关于重新排序指令之类的事情,这通常发生在纳秒级。更强的内存顺序不会让你的数据传输得更快;它甚至可能会减慢你的程序。
误解:禁用优化意味着我不需要关心内存顺序。
编译器和处理器都在使事情以不同于我们预期的顺序发生方面发挥了作用。禁用编译器优化不会禁用编译器中所有可能的转换,也不会禁用导致指令重新排序和类似的潜在问题行为的处理器功能。
误解:使用不重新排序指令的处理器意味着我不需要关心内存顺序。
一些简单的处理器,例如小型微控制器中的处理器,只有一个内核,并且一次只能执行一条指令,全部按顺序执行。然而,虽然在此类设备上内存顺序不正确导致实际问题的可能性要低得多,但编译器仍有可能根据不正确的内存顺序做出无效假设,从而破坏您的代码。除此之外,同样重要的是要认识到,即使处理器没有乱序执行指令,它可能仍然具有与内存顺序相关的其他功能。
误解:宽松的操作是免费的。
这是否属实取决于您对“免费”的定义。的确, Relaxed 是最有效的内存顺序,而且它比其他顺序快得多。甚至在所有现代平台上,宽松的加载和存储操作都可以编译为与非原子读写相同的处理器指令。
如果原子变量仅由单个线程使用,那么与非原子变量在速度上的任何差异很可能是因为编译器具有更多自由并且在优化非原子操作方面更有效。 (编译器倾向于避免对原子变量进行大多数类型的优化。)
但是,从多个线程访问同一内存通常比从单个线程访问它要慢得多。当其他线程开始重复读取变量时,连续写入原子变量的线程可能会明显变慢,因为处理器内核及其缓存现在必须开始协作。
我们将在第 7 章探讨这种影响。
误解:顺序一致的内存顺序是一个很好的默认设置,而且总是正确的。
撇开性能问题不谈,顺序一致的内存顺序通常被视为默认的完美内存顺序类型,因为它有强大的保证。确实,如果任何其他内存顺序是正确的, SeqCst 也是正确的。这可能听起来好像 SeqCst 总是正确的。然而,无论内存顺序如何,并发算法完全有可能是不正确的。
更重要的是,在阅读代码时, SeqCst 基本上告诉读者:“这个操作取决于程序中每个单独的 SeqCst 操作的总顺序”,这是一个令人难以置信的深远主张。如果可能的话,如果使用更弱的内存顺序,相同的代码可能更容易审查和验证。例如, Release 有效地告诉读者:“这与对同一变量的获取操作有关”,这在形成对代码的理解时涉及的考虑要少得多。
建议将 SeqCst 视为警告标志。在野外看到它通常意味着发生了一些复杂的事情,或者只是作者没有花时间分析他们的内存顺序相关假设,这两者都是额外审查的原因。
误解:顺序一致的内存顺序可用于“释放加载”或“获取存储”。
虽然 SeqCst 可以代表 Acquire 或 Release ,但它不是以某种方式创建获取存储或释放加载的方法。那些仍然不存在。 Release只适用于store操作,acquire只适用于load操作。
例如, Release-store 不与 SeqCst-store 形成任何释放-获取关系。如果您需要它们成为全局一致顺序的一部分,则两个操作都必须使用 SeqCst 。
总结
所有原子操作可能没有全局一致的顺序,因为不同线程的事情看起来可能以不同的顺序发生。
然而,每个单独的原子变量都有自己的总修改顺序,与内存顺序无关,所有线程都同意这一点。
操作顺序是通过先行发生关系正式定义的。
在单个线程中,每个操作之间都存在先行发生关系。
生成(spawn)线程发生在生成线程所做的所有事情之前。
线程所做的一切都发生在加入(join)该线程之前。
解锁一个互斥锁发生在再次锁定该互斥锁之前。
从释放存储中获取加载值建立了一个先行发生关系。该值可以通过任意数量的获取和修改以及比较和交换操作进行修改。
如果存在的话,消费加载将是获取加载的轻量级版本。
顺序一致的顺序会导致全局一致的操作顺序,但几乎从来没有必要,并且会使代码审查更加复杂。
栅栏允许您组合多个操作的内存顺序或有条件地应用内存顺序。